Tokenization, Cost, and Linguistic Inequality
(In a hurry? Visit https://ml-workbench.onrender.com/)
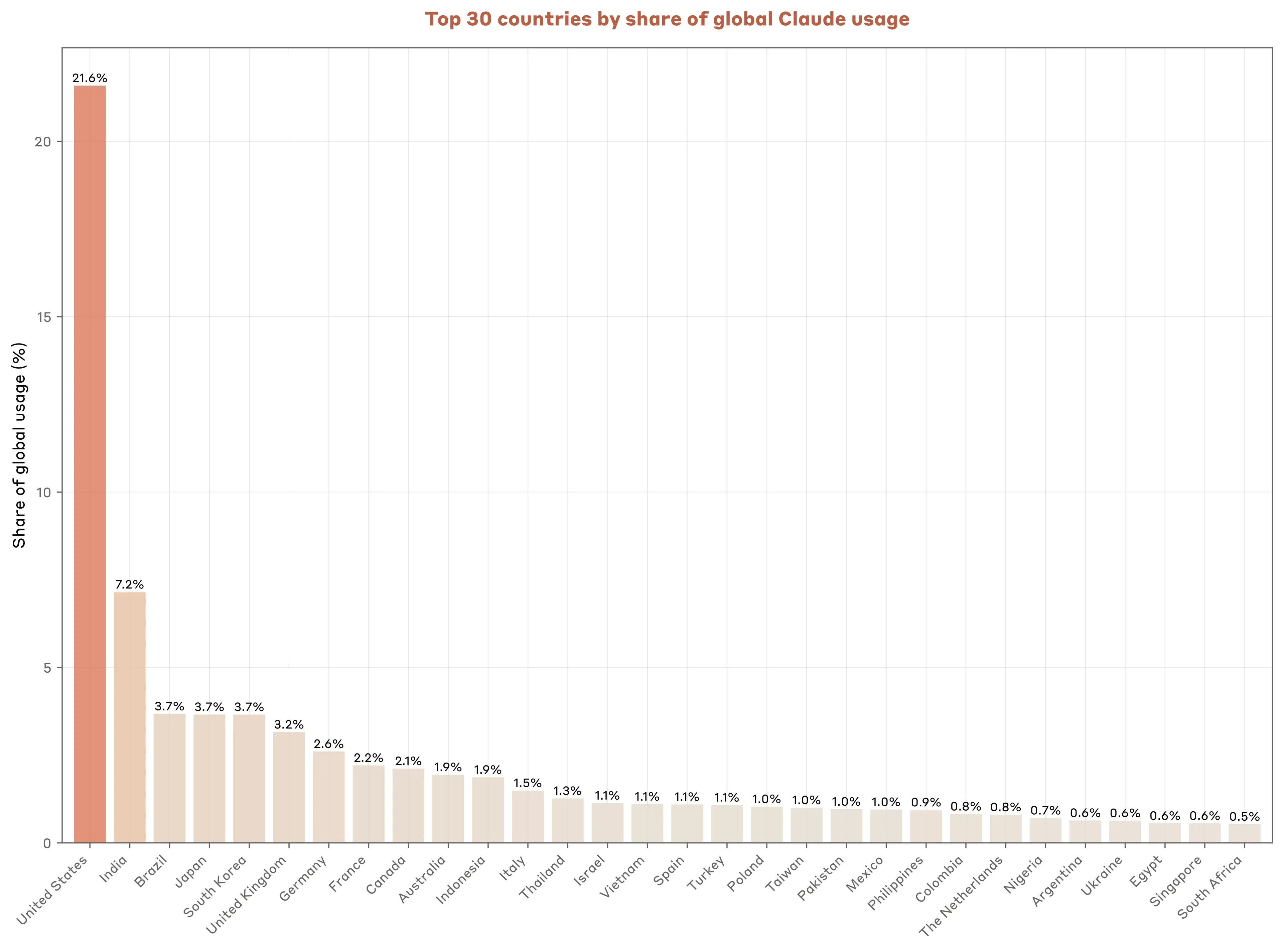
In LLM evaluation conversations, tokenization is often seen as a low-level optimization problem, but it can disproportionately rewrite cost, latency, and context-window assumptions for non-English users as models scale. In fact, in 2025, (70.2% of Claude.ai usage) came from non-English native-speaking countries, and many of those requests required more compute, longer processing times, and increased context consumption. An overlooked factor contributing to this is tokenization.
{kind=link}
Popular LLMs use tokenization to build vocabularies using training data where language like Hindi, Arabic, and Swahili are less prevalent and as a result these scripts are given less efficient coverage. It’s almost like being charged by the letter instead of the word. The LLM has to break these scripts down into many smaller chunks, meaning it takes more effort and costs more money just to communicate the exact same meaning.
A few weeks ago, I started looking into evaluating multilingual LLMs. I expected to spend my time comparing deployable models, price tables, and context windows, but quickly realised I needed to dig into how tokenization behaves across natural languages first.
Based on that, I want to share a guiding framework for evaluating LLM tokenizer families and their models. I'll also show how looking closely at tokenizers helps explain:
- Why the same feature can have very different economics across languages
- Why some model families feel much more multilingual than others before you ever run a task benchmark
- Why "best tokenizer" and "best deployed option" are not the same question
- Why controlled tests (strict aligned evidence) and real-life observations (naturalistic exploratory evidence) should not be mixed together
Before we get into it, let's dive into the basics of tokenization:
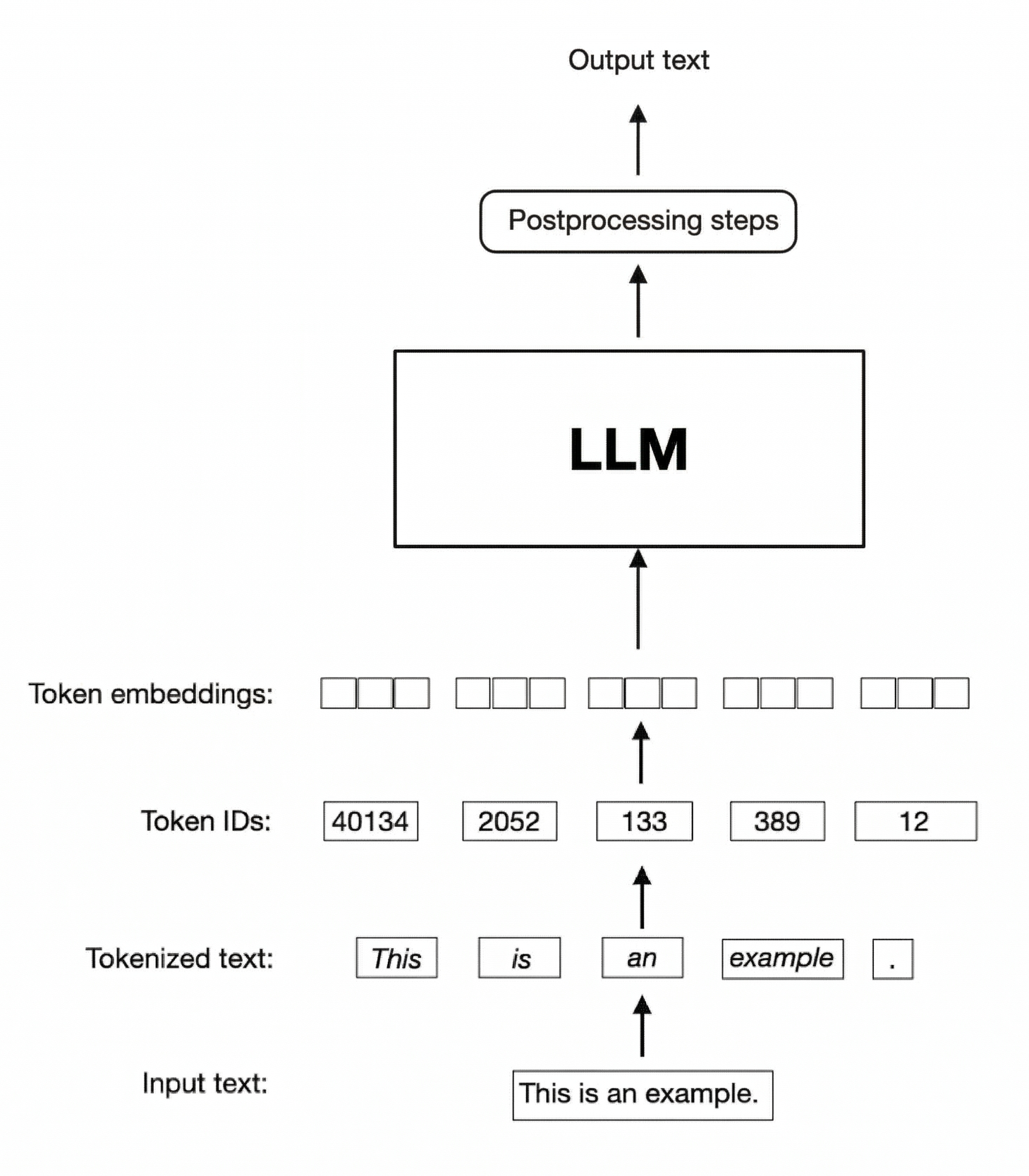
Basics: Decoding Text
Understanding tokenization starts with how computers actually "see" text as a string of bytes. Even though we use a universal standard called UTF-8, it doesn't treat every language the same. Some language scripts take up much more digital room than others to say the same thing. While English is quite compact, languages like Arabic, Chinese, or Japanese have a much larger byte footprint from the very start. So, before the tokenizer even begins its work, different languages are already arriving with completely different levels of bulk. Grammar makes it even trickier to compare. Some languages pack a ton of information into just one word or a short string of characters, while others spread it out. For example:
The equivalent of 'The sun rises in the east.' (6 words) in Hindi is 'सूरज पूर्व में उगता है' (5 words).
This means that even when two phrases have the "same meaning," they can look totally different to a computer, making it really hard to treat them as equals.
Basics: Tokenization
Instead of seeing a string of bytes, LLMs see tokens, which are learned symbols via an approach called Byte Pair Encoding representing everything from full words to small fragments of script.
BPE learns a token from a training corpus by starting with an initial set of possible characters, and then repeatedly merging the most common pair of tokens into a new token that is added to its growing vocabulary tokenizers used in modern LLMs are subword tokenizers. They try to balance compression and flexibility by assigning tokens to the most frequent reusable chunks of text. (Gage, 1995)
When that works well, tokens line up reasonably closely with meaningful units. When it works poorly, text gets broken into many smaller and less useful pieces.
For example, the tokenizer o200k_base (used in ChatGPT 5.x) breaks the same sentence into very different pieces depending on the language:
The sun rises in the east.
सूरज पूर्व में उगता है
To understand why models struggle more with some languages than others, you have to look at the relationship between tokenizer design and training data. Tokenizers are usually built from the same broad data distribution approach used to train the model. That means high-resource languages like English tend to get better vocabulary coverage, while lower-resource languages like Hindi, Bengali, Navajo and Swahili are more likely to be represented by smaller, less efficient fragments.
That imbalance matters during both model training and inference. In English, tokens often capture whole words or large subword units. In Hindi, Arabic, or other under-covered languages, tokens are more likely to capture partial pieces. Ten English tokens can represent much more usable meaning than ten Hindi tokens.
This fragmentation creates several downstream consequences:
- more tokens means more processing cost
- more tokens means less usable context
- more tokens means more opportunities for sentence generation to drift token by token
- more fragmentation usually means weaker practical coverage for that script or language
ML Workbench
I built ML Workbench to explore how multilingual tokenizer families behave across a fixed set of languages and how those differences carry through to real model pricing. My goal is not to answer every multilingual question at once, but to keep one claim clean: when the same meaning is aligned, how differently do tokenizer families behave, and what happens when those differences hit real model pricing and context limits?
Open-source repository: You can clone it and run benchmarks locally: https://github.com/707/ml-workbench
Interface: In addition to the code for running the benchmarks, I also made a live interface: https://ml-workbench.onrender.com/
The workbench combines a few different views of 10 natural languages in 3 LLM model families (6 tokenizers in total).
The app has four main views:
Benchmarkmeasures tokenization behavior under either strict aligned evidence or exploratory streaming text.Catalogmaps tokenizer families to deployable models.Scenario Labtranslates tokenizer-led inflation into production-facing inference metrics like cost and context loss.Auditwhich records formulas, sources, and provenance rules.
Datasets and Methodology
The workbench uses two benchmarking lanes, and I think keeping them separate is important.
- Strict Evidence uses a snapshot of FLORES 200 dataset, a multilingual benchmark built by Meta from aligned translations. Because sentence meanings are aligned across languages, it is the safest option to compute Relative Token Cost and compare tokenizer families. Scenario Lab is also tied to this lane.
- Streaming Exploration uses FineWeb2 dataset derived from CommonCrawl. This exists because real user written text is messier and I wanted to compare how they perform against stricter data. This lane is commonly used as a diagnostic lens to help production teams with heuristic signals on a model.
The tool also maps tokenizer evidence to deployable models through OpenRouter's live model metadata, which lets the workbench map tokenizer behavior to real-world-pricing and model performance.
Let's use the workbench to evaluate languages across the GPT-2 legacy, OpenAI o200k, Llama 3 and Qwen 2.5 family of tokenizers using the strict evidence approach.
Relative Token Cost (vs English)
Relative Token Cost, or RTC, is the clearest metric in the workbench.
It is simply:
RTC = source_tokens / english_tokens
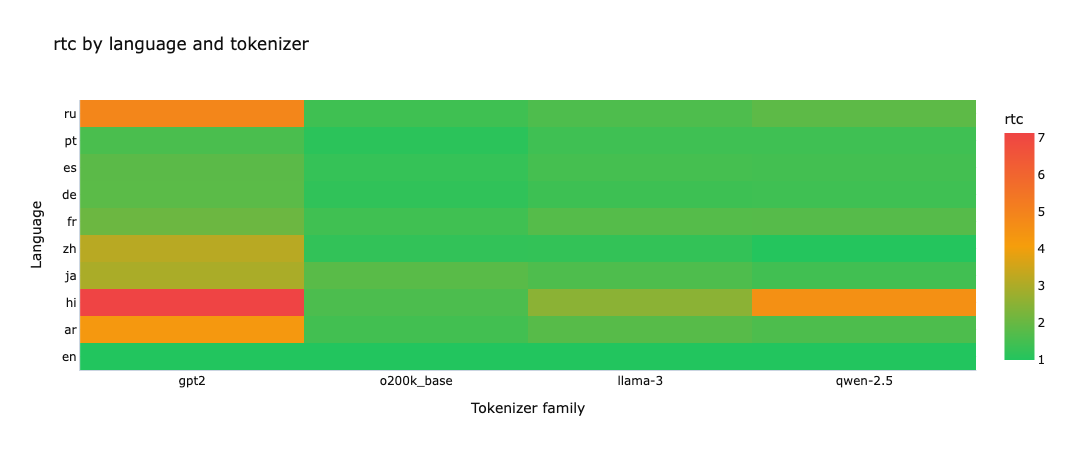
The lower the better. A value of 1.0x means the language takes the same number of tokens as aligned English. A value of 2.0x means it needs twice as many tokens to say the same thing.
Hindi is the harshest case with gpt2 landing at 7.13x, qwen-2.5 at 4.5x, llama-3 at 2.5x, and o200k_base at 1.6x. That is a wide spread for equivalent meaning, and it immediately tells you that tokenizer choice can dominate multilingual cost before model selection even starts.
Chinese Mandarin is where the Qwen result becomes striking, qwen-2.5 comes in at 1.0227x, very close to English while o200k_base, which was released by OpenAI in the same year lags behind at 1.23x. This fits what you would expect from a Chinese tokenizer with stronger Chinese coverage
Efficiency (Bytes per Token)
Bytes per token is the next most useful metric, but it is easier to misread. It asks how much raw UTF-8 text gets compressed into each token:
bytes_per_token = total_bytes / total_tokens
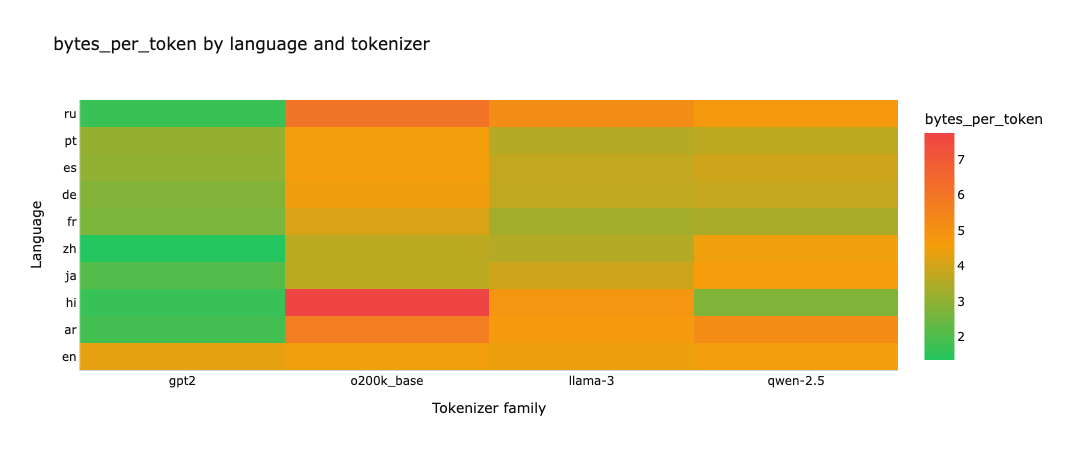
Higher is usually better. If a tokenizer packs more bytes into each token, it is usually compressing that language more efficiently. But this metric requires caution because high byte-per-character scripts, such as Hindi, can artificially inflate efficiency scores without actually being well aligned to meaningful units. That is why I treat bytes per token as a companion to RTC, not as a replacement for it.
Coverage (Unique Tokens)
Coverage is one of the more revealing metrics in the app, especially when read cautiously.
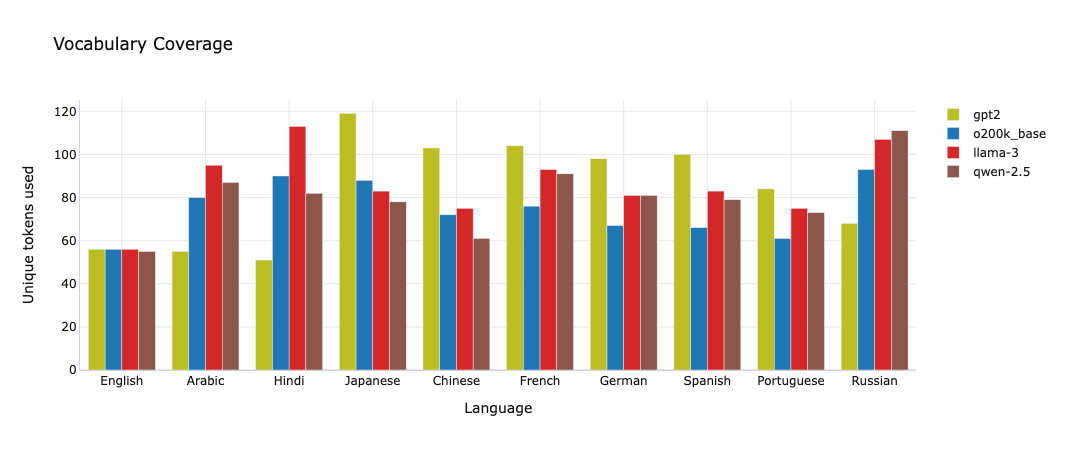
The workbench computes unique_tokens as the number of distinct token IDs used when encoding the selected benchmark text. Higher values often suggest broader practical coverage of that language's script or writing patterns.
Japanese and Chinese are good examples of taking caution. gpt2 shows the highest unique-token count for both languages but it does not win on RTC. qwen-2.5 is still the most efficient tokenizer for both. So treat coverage as informative, but it is not a universal proxy for overall tokenization quality.
More Fragmentation Signals
The next set of metrics are best read together.
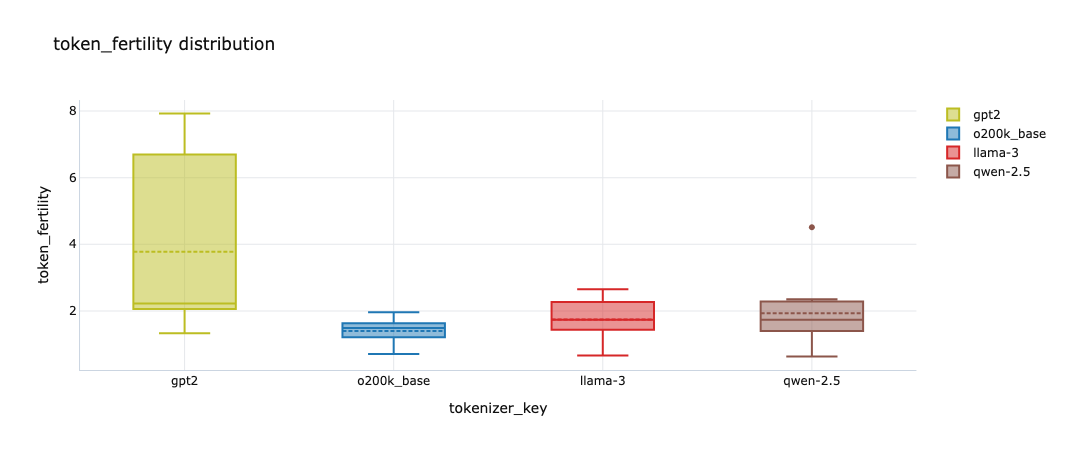
The word split rate view asks a simple question: how often does the tokenizer break a natural unit into multiple pieces? This is surfaced through continued_word_rate, and lower is generally better.
Subword fertility asks the related question: how many token pieces do I need per word or character on average? A value close to 1.0 is a good sign. Higher values mean the text is being chopped up more aggressively.
In the exploratory lane, GPT-2 legacy becomes the obvious outlier on fertility, reporting a range of 1.33 to 7.93 with a much wider spread than the newer families. These are the kinds of relationships I was hoping the dual-lane approach would surface. The strict lane tells me what is safely true under aligned conditions. The streaming lane tells me whether that same rough pattern still shows up once the text gets messier. In this case, it does.
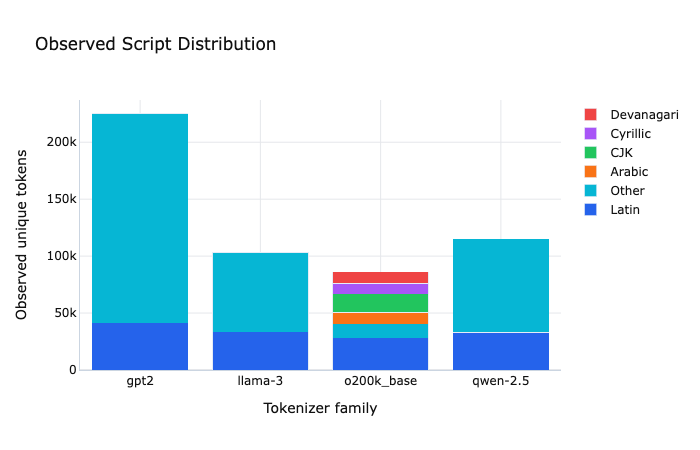
The Observed Composition tab helps explain why. It shows which scripts the tokenizer pieces actually came from on the selected rows. I use it less as a ranking view and more as a diagnostic sanity check. If a tokenizer looks good on a headline metric but the observed composition suggests weak or awkward script-specific coverage, that is worth paying attention to.
Scenario Lab for Models
I wanted a Scenario Lab to go beyond simple tokenizer tests. Focusing only on a model’s 'taste' ignores the structural costs of scaling that model across real users. Starting with tokenizer evidence gives a clearer picture of where multilingual pressure enters the system.
For this scenario, I used:
- languages: English, Arabic, Hindi, Japanese
- benchmark tokenizers:
Llama 3 family,Mistral family,Qwen 2.5 family - monthly requests:
100,000 - average input tokens:
600 - average output tokens:
250 - reasoning share:
0.1
This is where things started to get more nuanced.
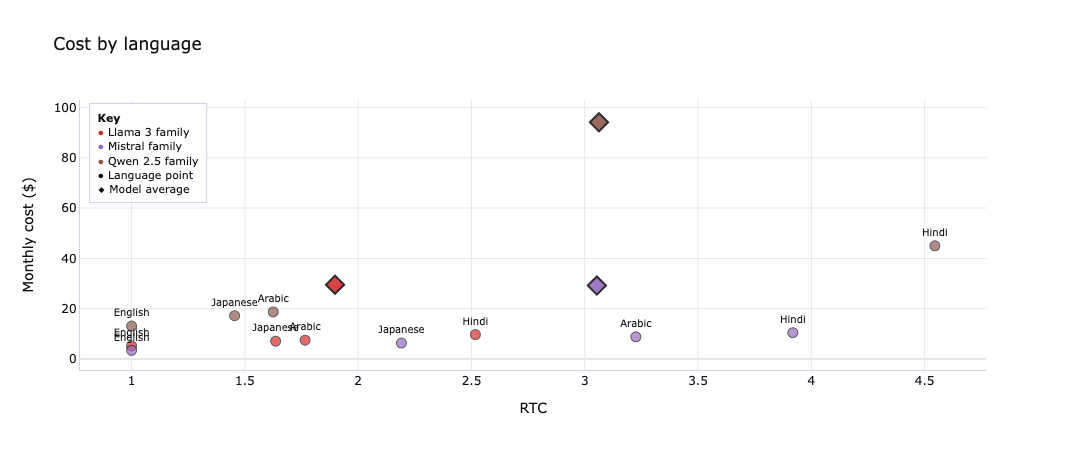
The first chart makes the main deployment lesson obvious: the best tokenizer is not always the cheapest deployed option. In this slice, Qwen 2.5 often looks strong at the tokenizer level, but it ends up with the highest average monthly cost. Hindi is the main reason. It contributes roughly $45 per month on its own at about 4.5 RTC, which pushes the family average sharply upward. Why does optimising for this matter? Because Hindi is the third most spoken language 609 million.
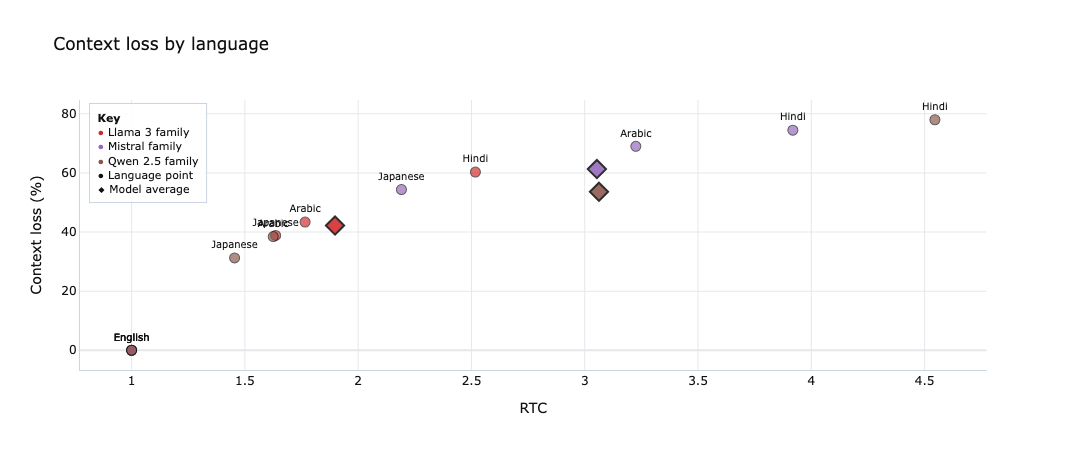
The second chart shows the same story from the context side. Hindi is again the clearest stress case, with context loss approaching 78% in the worst case shown here. Arabic (335M speakers) is the next important language to watch: not as severe as Hindi, but still meaningfully more expensive and more context-hungry than English or Japanese.
That is the decision trap I wanted the tool to surface. "Best tokenizer" and "best model to ship" are often different questions. If your product depends on Hindi or Arabic, the economics and context fit of the deployed model can change materially even when the underlying task is the same.
Closing
If I had to turn this into a practical workflow for model selection, it would look like this:
- Benchmark tokenizer families on aligned text
- Inspect fragmentation when a chart looks suspicious
- Sanity-check the pattern on more naturalistic text
- Map tokenizer families to deployable models
- Translate token inflation into cost and context consequences
- Then argue about which model to ship
I still think the most useful part of the workbench is that it makes a boring but consequential layer legible. Tokenization is easy to ignore right up until it starts quietly rewriting your multilingual cost model.
There are still several open questions I find interesting:
- which tokenization metric matters most for downstream multilingual quality
- how much tokenizer coverage and efficiency can be improved at the same time
- whether tokenizer metrics alone can predict enough multilingual capability to make model screening faster
I hope you've found the ml-workbench as useful as I did. I’ve tested ml-workbench quite a bit, but to get this right, the tool needs more eyes and more testing across all kinds of different languages and use cases so jump in and help out if you can! Whether you’re reporting a bug, suggesting a new metric, or adding a tokenizer I missed, your input makes the whole thing better for everyone.
Also, a quick note to the AI labs: if you’re working on a private model but are okay with sharing your tokenizer's performance data, please get in touch. The rest of us would learn a lot from seeing how the biggest systems actually handle different languages.
Appendix:
- Tokenization fragmentation framing was sharpened by papers like Tokenization Disparities as Infrastructure Bias and Reducing Tokenization Premiums for Low-Resource Languages in LLMs. Both are useful because they treat tokenization not as trivia, but as a system-level input into fairness, access, cost, and quality.